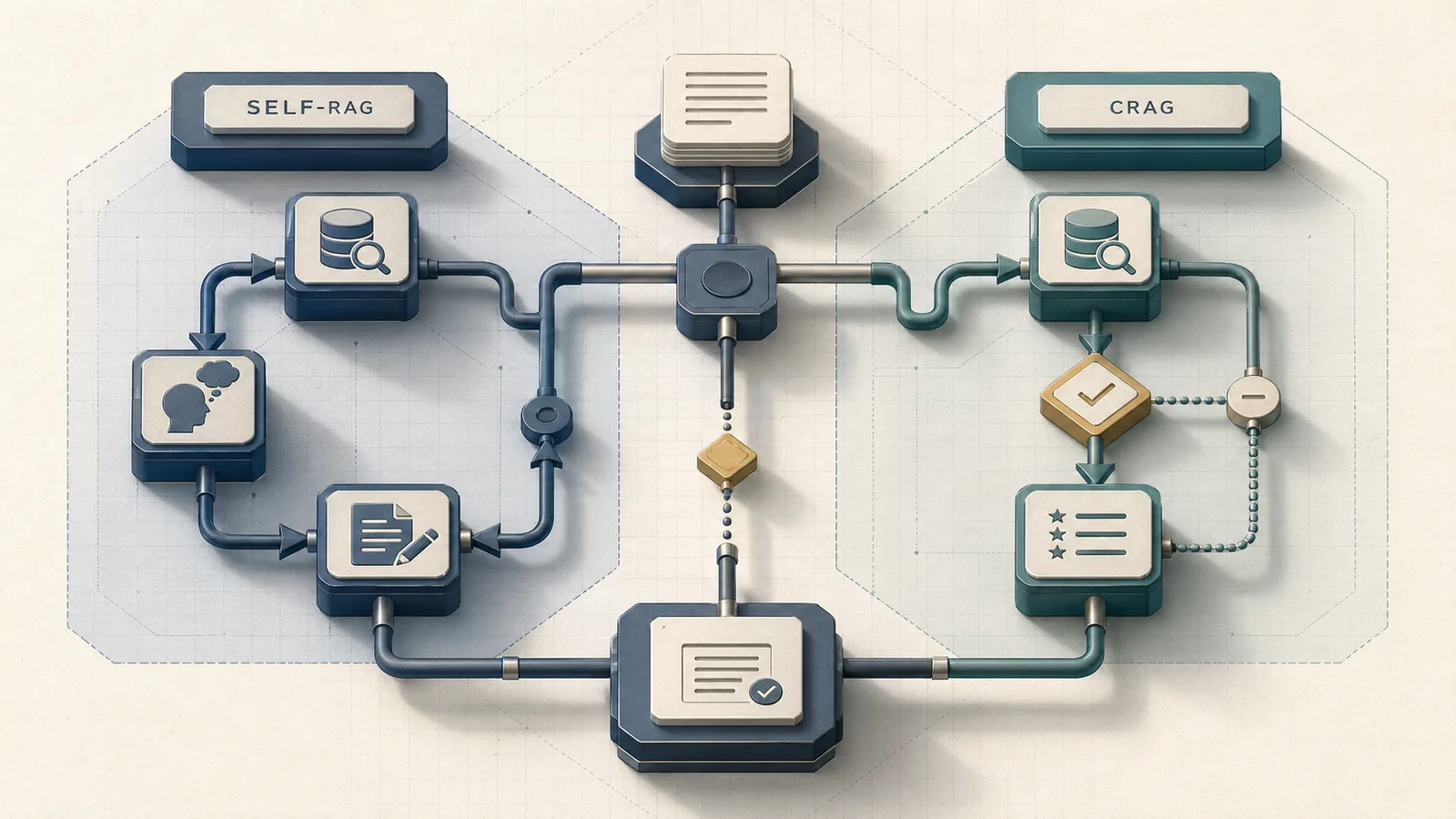
How we compared Self-RAG and CRAG in LangGraph
Both Self-RAG and CRAG are implemented as LangGraph state machines in the same LangChain engineering post published February 7, 2024. The post frames them explicitly as "flow engineering" examples for self-reflective RAG: "Here, we show that LangGraph can be easily used for 'flow engineering' of self-reflective RAG." That framing matters — both patterns sit above basic RAG on the complexity ladder, and the post treats them as alternative orchestration strategies rather than complementary layers.
At a Glance: Self-RAG is the better fit when answer grounding and multi-hop correction matter more than latency; CRAG is the better fit when retrieval quality, freshness, and a web-search fallback are the primary concerns.
The comparison axes that matter for a production decision are retrieval quality lift, per-query LLM call count, end-to-end latency, implementation complexity, observability, and whether a web-search fallback is structurally required. The official LangChain examples demonstrate both flows but deliberately omit a decision rubric across those dimensions. This article supplies it.
One hard constraint from the source material: no authoritative shared benchmark publishes side-by-side latency or call-count numbers for Self-RAG versus CRAG under a matched workload. Where the table below shows relative ordering rather than absolute numbers, that framing is intentional and honest.
| Criterion | Self-RAG | CRAG |
|---|---|---|
| Retrieval quality lift | High — graded at retrieve, support, and useful stages | Moderate-to-high — graded at retrieval-quality stage only |
| LLM call count per query | Higher — multiple reflection passes per answer | Lower — one evaluator call gates the path |
| End-to-end latency | Higher — reflection loops add inference steps | Lower (no fallback) / higher (with web search) |
| Implementation complexity | Higher — multi-stage control graph with looping | Moderate — linear evaluator → rewrite/fallback → generate |
| Observability surface | Larger — retrieve, grade, support, useful nodes all traceable | Smaller — evaluator score and fallback trigger are the key signals |
| Web-search fallback | Not structurally required | Architecturally central |
Self-RAG vs CRAG at a glance
Self-RAG ("Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection") controls retrieval and generation through reflection tokens that gate four decisions per query: whether to retrieve, whether retrieved passages are relevant, whether the generation is supported by the passage, and whether the final answer is useful. CRAG ("Corrective Retrieval Augmented Generation") takes a narrower approach: a lightweight retrieval evaluator scores the initial passage set and routes the query along one of three paths — proceed, rewrite, or fall back to web search.
The operational distinction is where correction happens. Self-RAG corrects throughout the generation process; CRAG corrects before generation begins. LangGraph encodes both as directed graphs with conditional edges, but the graphs differ significantly in node count and loop structure.
| Dimension | Self-RAG | CRAG |
|---|---|---|
| Correction point | Pre-generation, mid-generation, post-generation | Pre-generation only |
| Primary failure mode addressed | Hallucination and unsupported answers | Weak or stale retrieval |
| Fallback mechanism | Internal re-retrieval loop | External web search |
| LangGraph graph topology | Cyclical with multiple grading nodes | Mostly linear with one decision fork |
| Best fit | Multi-hop QA, strict grounding requirements | Ambiguous queries, fresh-knowledge requirements |
Self-RAG in LangGraph: when reflection loops help
Self-RAG's defining characteristic in a LangGraph implementation is that LLM inference fires multiple times per user query — once to decide whether to retrieve, once to grade passage relevance, once to assess whether the generation is supported by the retrieved passage, and once more to assess whether the answer is useful. LangChain's own evaluation framework confirms the core failure mode this addresses: "Faithfulness evaluation specifically checks whether agent responses can be logically inferred from the provided context." Self-RAG builds that faithfulness check directly into the generation loop rather than bolting it on post-hoc.
Production Note: Each reflection pass is a separate LLM call. For a query that triggers retrieve → grade → generate → support-check → regenerate, you can realistically see 4–6 inference calls where a naive RAG pipeline makes 1. The exact multiplier is workload-dependent and should be measured against your latency budget before committing to Self-RAG. The official LangChain examples are notebook-scale demonstrations; they do not publish normalized cost-per-query figures for Self-RAG versus a baseline.
Pro Tip: Self-RAG's multi-call overhead is most justified when retrieval is not the primary problem — that is, when your vector index (Pinecone, Milvus, or an HNSW-backed store) retrieves plausible passages but the LLM still generates unsupported or hallucinated answers. If your RAGAS faithfulness score is low while recall is adequate, Self-RAG targets the actual failure mode. If recall is the problem, CRAG is a better fit.
How reflection tokens control retrieve, support, and useful decisions
The Self-RAG paper introduces reflection tokens as special control signals that a fine-tuned model learns to emit at inference time. These tokens implement a multi-stage decision process over four questions that the LangGraph flow exposes as conditional edges:
| Decision type | Reflection token type | LangGraph action on failure |
|---|---|---|
| retrieve | Retrieve token | Branch to retrieval node |
| relevance / grade | ISREL token | Loop back and re-retrieve |
| support | ISSUP token | Regenerate with the same or new passage |
| useful | ISUSE token | Loop back to retrieve or halt |
In the LangGraph notebook simplification, these four token types collapse into grading functions that evaluate retrieval relevance and generation faithfulness sequentially. The exact thresholds are implementation-specific and not standardized — the paper establishes the control scheme, but production deployments on Llama 3.1 70B or GPT-4 class models must calibrate graders on their own data.
Where Self-RAG fits: multi-hop questions and strict grounding
Self-RAG's orchestration overhead pays off when a single retrieval pass cannot synthesize a correct answer — specifically, multi-hop questions where the answer requires chaining evidence across multiple retrieved passages, and compliance or legal contexts where unsupported answers carry real cost. The LangChain agentic-RAG docs characterize this as "an LLM-powered agent decides when and how to retrieve during reasoning," which is the right framing: retrieval is on-demand per reasoning step, not a single pre-generation call.
Pro Tip: Self-RAG is strongest when answer quality matters more than latency and when strict grounding — measured as RAGAS faithfulness — is a hard product requirement. If a 500ms increase in P95 latency is acceptable in exchange for a 15-point faithfulness lift on your evaluation set, Self-RAG's control logic is worth the overhead. If your SLA is sub-300ms, profile the actual call count on your workload first.
CRAG in LangGraph: when retrieval correction is the real problem
CRAG addresses a different failure mode: the initial retrieved documents are weak, ambiguous, or stale. The CRAG paper states directly that "a lightweight retrieval evaluator is to estimate and trigger three knowledge retrieval actions discriminately" and that "large-scale web searches are utilized as an extension for augmenting the retrieval results." The LangGraph implementation encodes this as a linear flow — retrieve, evaluate, branch — before generation starts.
| Evaluator score | CRAG action | LangGraph edge |
|---|---|---|
| High relevance | Proceed to generation | Direct edge to generate node |
| Ambiguous / partial relevance | Rewrite query, re-retrieve | Loop edge to query-rewrite node |
| Low relevance / irrelevant | Fall back to web search | Edge to web-search tool node |
CRAG is the right choice when retrieval ambiguity is the root cause of answer degradation. It adds one evaluator LLM call and, on fallback paths, one external search call — substantially fewer inference passes than Self-RAG's reflection loops.
How the retrieval evaluator gates weak or irrelevant passages
CRAG uses a lightweight retrieval evaluator before generation, and that evaluator routes each query through three actions: pass, rewrite, or fallback. If the evaluator scores the initial passage set as high-quality, no additional retrieval happens and generation proceeds immediately — this is the happy path. If scoring is ambiguous, CRAG rewrites the query and re-retrieves from the same vector store; this path adds one rewrite LLM call and one additional retrieval. If scoring is definitively poor, CRAG discards the vector store results and issues a web search.
| Path | Retrieval quality signal | CRAG action |
|---|---|---|
| Pass | High relevance | Proceed to generation |
| Rewrite | Ambiguous / partial relevance | Rewrite query and re-retrieve |
| Fallback | Low relevance / irrelevant | Fall back to web search |
The score thresholds that separate these three paths are implementation details not standardized in the official LangGraph notebook. In practice, you must calibrate the evaluator against your corpus using your own retrieval hit-rate data before relying on the defaults.
Why web-search fallback matters for ambiguous or stale queries
Web-search fallback is CRAG's core architectural differentiator. For queries about recent events, rapidly changing technical specifications, or topics where your internal knowledge base is sparse, the fallback converts a retrieval failure into a viable answer path. The CRAG paper's abstract frames this as solving the problem of "static and limited corpora" that "yield sub-optimal documents."
Pro Tip: Web-search fallback earns its cost when your query distribution includes a meaningful fraction of freshness-sensitive or out-of-distribution questions. If more than 10–15% of your production queries fall outside your corpus's coverage window, CRAG's fallback can deliver faithfulness lift that reranking alone cannot provide.
Watch Out: Web-search fallback adds variable latency and introduces external vendor dependency. A 2026 reproduction analysis of the original CRAG implementation noted that it relies on the Google Search API, proprietary LLaMA-2 fine-tuned weights, and deprecated OpenAI API calls, signaling that production deployments must validate their search integration independently. If your queries are not freshness-sensitive, the fallback may introduce latency with no quality benefit over reranking the existing passage set.
Benchmarking the trade-off: retrieval quality, latency, and LLM calls
No authoritative source publishes a direct, matched-workload benchmark comparing Self-RAG and CRAG on the same dataset with the same base model — this is a genuine gap in the published record. The table below presents a benchmark template using the evaluation dimensions that LangChain's Ragas + LangSmith evaluation guide recommends: faithfulness, relevancy, and recall. Operators running either pattern should populate these columns against their own evaluation set using LangSmith; the relative ordering reflects the architectural trade-offs, not a single controlled experiment.
| Metric | Naive RAG (baseline) | CRAG (happy path) | CRAG (with fallback) | Self-RAG |
|---|---|---|---|---|
| Answer faithfulness | baseline | template | template | template |
| Retrieval hit rate | baseline | template | template | template |
| LLM calls per query | 1 | 2 | 3 | 4–6 |
| Relative latency vs. naive RAG | 1× | template | template | template |
Production Note: These relative orderings hold under typical production conditions, but the absolute numbers depend on your base model, vector index performance, and whether reflection loops actually fire. LangChain explicitly notes that "Ragas provides you with a few insightful metrics, it does not help you in the process of continuously evaluation of your QA pipeline in production — but this is where LangSmith comes in." Treat any single benchmark number as a starting point, not a deployment guarantee.
What to measure in production RAG evaluations
LangChain's evaluation guidance centers three metrics: "Measure faithfulness, relevancy, and recall to build reliable QA systems." For corrective retrieval patterns specifically, a fourth metric matters operationally: correction trigger rate — the fraction of queries that activate the evaluator's rewrite or fallback path (CRAG) or any reflection loop (Self-RAG). A high trigger rate signals corpus coverage problems that neither pattern alone can fix.
| Metric | What it measures | Unit / note | Which pattern it stresses |
|---|---|---|---|
| Answer faithfulness | Whether the response is grounded in retrieved context | score / % | Self-RAG (support-check loop) |
| Retrieval relevance | Whether retrieved passages match the query | score / % | CRAG (evaluator gate) |
| Recall | Whether the correct answer appears in retrieved passages | score / % | Both equally |
| Correction trigger rate | Fraction of queries activating correction logic | % of queries | Diagnostic for both |
| TTFT / P95 latency | End-to-end response time at production load | ms | Self-RAG (more sensitive due to call count) |
LangSmith's continuous evaluation capability exists precisely to prevent overfitting to a single benchmark. Run both patterns on a sample of your actual production traffic — not a benchmark proxy — before committing to one. Pay particular attention to fallback hit rate for CRAG and loop iteration count for Self-RAG; these are the leading indicators of operational cost. A 2026 reproduction analysis of the original CRAG paper also noted that implementation discrepancies (paid search APIs, deprecated model weights) can make published accuracy numbers non-reproducible, reinforcing the case for evaluating on your own stack.
Decision matrix: which corrective retrieval pattern should you ship?
Neither Self-RAG nor CRAG is universally better. The CRAG paper describes Self-RAG as a method to "self-correct the results of retriever," and Self-RAG's design uses "reflection tokens" to control retrieval and generation quality. These are complementary solutions to different problems. The decision turns on four variables: latency budget, whether retrieval ambiguity or answer synthesis is the primary failure mode, freshness dependence, and how much orchestration complexity your team can instrument and maintain.
| Condition | Recommended pattern | Rationale |
|---|---|---|
| Latency budget > 3× naive RAG AND faithfulness is the KPI | Self-RAG | Reflection loops target answer grounding directly |
| Latency budget 1.5–2.5× naive RAG AND retrieval relevance is the failure mode | CRAG (no fallback path) | One evaluator call is enough |
| Queries are freshness-sensitive or out-of-corpus | CRAG (with web fallback) | Web search handles coverage gaps |
| Multi-hop reasoning across multiple sources required | Self-RAG | On-demand retrieval per reasoning step |
| Team has limited LangSmith instrumentation | CRAG | Fewer trace nodes to monitor |
| Latency budget ≤ naive RAG AND corpus is high-quality | Neither — use reranking | Corrective overhead not justified |
Choose Self-RAG when control logic and support checks matter most
Self-RAG is the right choice when the primary production complaint is that answers sound plausible but are not grounded — the hallucination problem that LangChain's evaluation framework describes as models generating "plausible-sounding text regardless of factual grounding." The support-check loop gates every answer against the retrieved evidence before the response reaches the user.
| Workload signal | Self-RAG fit |
|---|---|
| RAGAS faithfulness below target despite adequate recall | Strong fit |
| Multi-hop questions requiring chained evidence | Strong fit |
| Compliance, legal, or medical contexts where unsupported answers carry cost | Strong fit |
| High-quality, multi-hop workloads with higher orchestration tolerance | Strong fit |
| Latency SLA under 500ms P95 | Poor fit without aggressive caching |
| Primary failure mode is stale or missing knowledge | Poor fit — use CRAG |
Choose CRAG when ambiguity and freshness dominate
CRAG addresses the case where the vector store itself is the problem — the CRAG paper explicitly targets "sub-optimal documents" from "static and limited corpora." If your production query logs show a high fraction of low-relevance retrievals or freshness failures (queries about events after your index cutoff), CRAG's evaluator-plus-fallback pattern corrects the right failure mode with fewer inference calls than Self-RAG.
| Workload signal | CRAG fit |
|---|---|
| High rate of low-relevance retrievals from vector store | Strong fit |
| Queries about recent events or rapidly changing topics | Strong fit (with web fallback) |
| Freshness-sensitive or low-relevance retrieval workloads | Strong fit (with web fallback) |
| Latency budget tighter than Self-RAG allows | Moderate fit (happy path is fast) |
| Corpus is current and high-quality | Weak fit — fallback will rarely fire |
| Primary failure mode is answer hallucination, not retrieval | Weak fit — use Self-RAG |
Where neither pattern is worth the overhead
If a reranker applied to an existing HNSW-backed Pinecone or Milvus index already meets your faithfulness and recall targets, neither CRAG nor Self-RAG justifies the overhead. LangChain's retrieval documentation describes agentic RAG as one point on a spectrum; basic retrieval remains appropriate when the model does not need to decide dynamically. The first step before adopting either corrective pattern is to measure RAGAS faithfulness, relevancy, and recall on your baseline — "Measure faithfulness, relevancy, and recall to build reliable QA systems" — and confirm that the baseline actually fails on your production distribution.
Watch Out: Corrective retrieval patterns are not free upgrades. Self-RAG can realistically multiply your LLM costs 4–6× per query depending on how often reflection loops fire. CRAG with web fallback adds external API dependency and variable latency. If your baseline RAG plus a cross-encoder reranker passes your quality bar, shipping either corrective pattern adds cost and operational surface without a return.
What the official LangGraph examples leave out
The LangChain agentic RAG blog post is the canonical reference for both patterns and covers their graph structure clearly. What it omits is a production decision framework: there is no guidance on which pattern to choose given a latency budget, no LLM call count comparison under matched workloads, no observability recommendation for distinguishing retrieval failures from synthesis failures, and no cost model for web-search fallback versus reflection loops.
| Coverage dimension | Official LangChain blog | Most derivative guides |
|---|---|---|
| Graph structure for each pattern | ✅ Full | ✅ Partial |
| Decision criteria for choosing a pattern | ❌ Absent | ❌ Absent |
| LLM call count comparison | ❌ Absent | ❌ Absent |
| Operational cost model | ❌ Absent | ❌ Absent |
| Web-search fallback trade-offs | ⚠️ Mentioned, not quantified | ❌ Absent |
| LangSmith observability guidance | ⚠️ Referenced | ❌ Absent |
The post's own framing — "LangGraph can be easily used for 'flow engineering' of self-reflective RAG" — positions it as a flow-engineering tutorial, not a production deployment guide. The gap is operational, not conceptual.
How competitor guides frame only one side of the trade-off
Most derivative explainers for Self-RAG and CRAG cover one pattern per article, naming the architecture and walking through graph nodes without comparing operational cost. A CRAG-only explainer will present the evaluator-plus-fallback flow as the correct approach to corrective RAG; a Self-RAG-only explainer will present reflection tokens as the correct approach. Neither establishes the conditions under which the other pattern is preferable.
| Coverage type | Self-RAG coverage | CRAG coverage | Decision framework |
|---|---|---|---|
| Official LangChain blog | ✅ | ✅ | ❌ |
| Typical derivative tutorials | Partial | Partial | ❌ |
| arXiv papers (per-pattern) | ✅ (arXiv:2310.11511) | ✅ (arXiv:2401.15884) | ❌ |
| This article | ✅ | ✅ | ✅ |
The actionable content gap is not explanation of how each pattern works — that material exists — but the comparative decision framework across retrieval quality, latency, LLM call count, and freshness handling.
Why LangSmith observability changes the production decision
LangSmith is not optional instrumentation for corrective retrieval patterns — it is the mechanism that makes the production decision legible. The LangChain evaluation blog is direct: "Ragas provides you with a few insightful metrics, it does not help you in the process of continuously evaluation of your QA pipeline in production — but this is where LangSmith comes in."
Production Note: For Self-RAG, the signals to trace are: how often does the retrieve decision fire, how often does the support check fail and trigger a regeneration loop, and what is the P95 loop iteration count per query. For CRAG, the signals are: evaluator score distribution, rewrite trigger rate, and fallback hit rate. Trace retries, evaluator scores, fallback hits, and loop counts in LangSmith so you can distinguish a retrieval coverage problem from an answer synthesis problem. LangSmith's per-run tracing exposes all of these as inspectable nodes, making it possible to tune evaluator thresholds and reflection graders against real production traffic rather than benchmark proxies.
FAQ on Self-RAG vs CRAG in LangGraph
What is the difference between Self-RAG and CRAG?
Self-RAG uses reflection tokens to make four decisions per query (whether to retrieve, whether passages are relevant, whether the generation is supported, whether the answer is useful) and applies correction throughout the generation process. CRAG uses a lightweight retrieval evaluator to score the initial retrieved passages and routes the query to one of three paths — proceed, rewrite, or fall back to web search — before generation starts. Self-RAG corrects answer synthesis; CRAG corrects retrieval quality.
Is Self-RAG better than CRAG?
Neither pattern dominates. Self-RAG is better when answer faithfulness and hallucination prevention are the primary quality requirements. CRAG is better when retrieval ambiguity, sparse coverage, or stale knowledge is the primary failure mode. The choice depends on where your baseline RAG pipeline actually fails.
Does Self-RAG require more LLM calls?
Yes. A single Self-RAG query can require 4–6 LLM calls depending on how many reflection loops fire. CRAG's happy path requires 2 calls (evaluator + generator); its fallback path requires 3 (evaluator + rewriter + generator after web search). The source material does not publish a universal multiplier because the exact count depends on how often correction actually triggers on a given workload.
When should you use CRAG?
Use CRAG when your vector store returns low-relevance passages on a meaningful fraction of production queries, when your queries are freshness-sensitive (events after your index cutoff), or when your latency budget cannot absorb Self-RAG's reflection loops. CRAG's web-search fallback targets coverage and freshness problems that reranking cannot solve.
How does LangGraph implement agentic RAG?
LangGraph encodes both Self-RAG and CRAG as directed state machines where nodes are LLM calls or tool invocations and edges are conditional on evaluator or grader outputs. Self-RAG's graph is cyclical with multiple grading nodes; CRAG's graph is mostly linear with one conditional branch. LangChain positions LangSmith as the continuous evaluation layer for both.
Pro Tip: If you are unsure which pattern fits your workload, run both on a 100-query sample from your production logs using LangSmith to capture per-trace call counts, evaluator scores, and faithfulness ratings. The comparison that matters is against your data, not against a benchmark proxy. Consult the decision matrix above to map what you find to the right production choice.
Sources & References
- Self-Reflective RAG with LangGraph — LangChain Blog — Primary source: official LangChain post introducing both Self-RAG and CRAG as LangGraph flow-engineering examples (published 2024-02-07)
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection (arXiv:2310.11511) — Original Self-RAG paper introducing reflection tokens and the retrieve/support/useful control scheme
- Corrective Retrieval Augmented Generation (arXiv:2401.15884) — Original CRAG paper introducing the lightweight retrieval evaluator and web-search fallback
- Evaluating RAG Pipelines with Ragas and LangSmith — LangChain Blog — Primary source for RAG evaluation metrics: faithfulness, relevancy, recall
- LangSmith Evaluations — LangChain's continuous production evaluation platform referenced for observability guidance
- LangChain LLM Evaluation Framework — Defines faithfulness as logical inferability from context; warns against plausible-sounding ungrounded text
- LangChain Retrieval Docs — Frames agentic RAG as LLM-powered on-demand retrieval during reasoning
- Open-source CRAG Reproduction Analysis (arXiv:2603.16169) — 2026 analysis noting original CRAG implementation dependencies on Google Search API and deprecated OpenAI calls
Keywords: Self-RAG, CRAG, LangGraph, LangChain, LangSmith, OpenAI, Llama 3.1 70B, Hugging Face Transformers, Milvus, Pinecone, HNSW, web search fallback, retrieval evaluator, reflection tokens, query rewriting
