What RAGchain solves in a production RAG stack
Standard LangChain RAG chains couple the retriever tightly to a single vector store, which works for demos but creates maintenance problems the moment production requirements diverge: one query type needs BM25 precision, another needs semantic recall, a third needs freshness weighting, and the vector DB that holds embeddings is not the same system that stores full document text. RAGchain addresses this directly. Its README defines the project as an "Extension of Langchain for RAG. Easy benchmarking, multiple retrievals, reranker, time-aware RAG, and so on," and its architectural core is the explicit separation of retrieval from storage.
The key design decision is stated plainly in the repository: "Retrieval saves vector representation of contents, and DB saves contents. We connect both with Linker." Every other module in the system — BM25, dense vector search, HyDE, MonoT5, UPR, TART, LLM-based reranking — slots into this retrieval-to-storage-to-ranking control flow without changing its shape. OCR loaders and time-aware RAG extend the corpus and the freshness logic without requiring a different pipeline contract.
Bottom Line: RAGchain's architectural contribution is not a new retrieval algorithm — it is a composition layer that decouples retrieval indexes from document storage through a Linker abstraction, then applies a swappable reranker stage after any combination of retrievers has produced a candidate set. Teams that hit the limits of single-retriever LangChain chains use this to compose BM25, dense search, and HyDE-style query expansion together, then pass the merged candidate pool to the reranker that matches their latency and quality budget — all without rewriting the pipeline wrapper.
How the RAGchain workflow is composed end to end
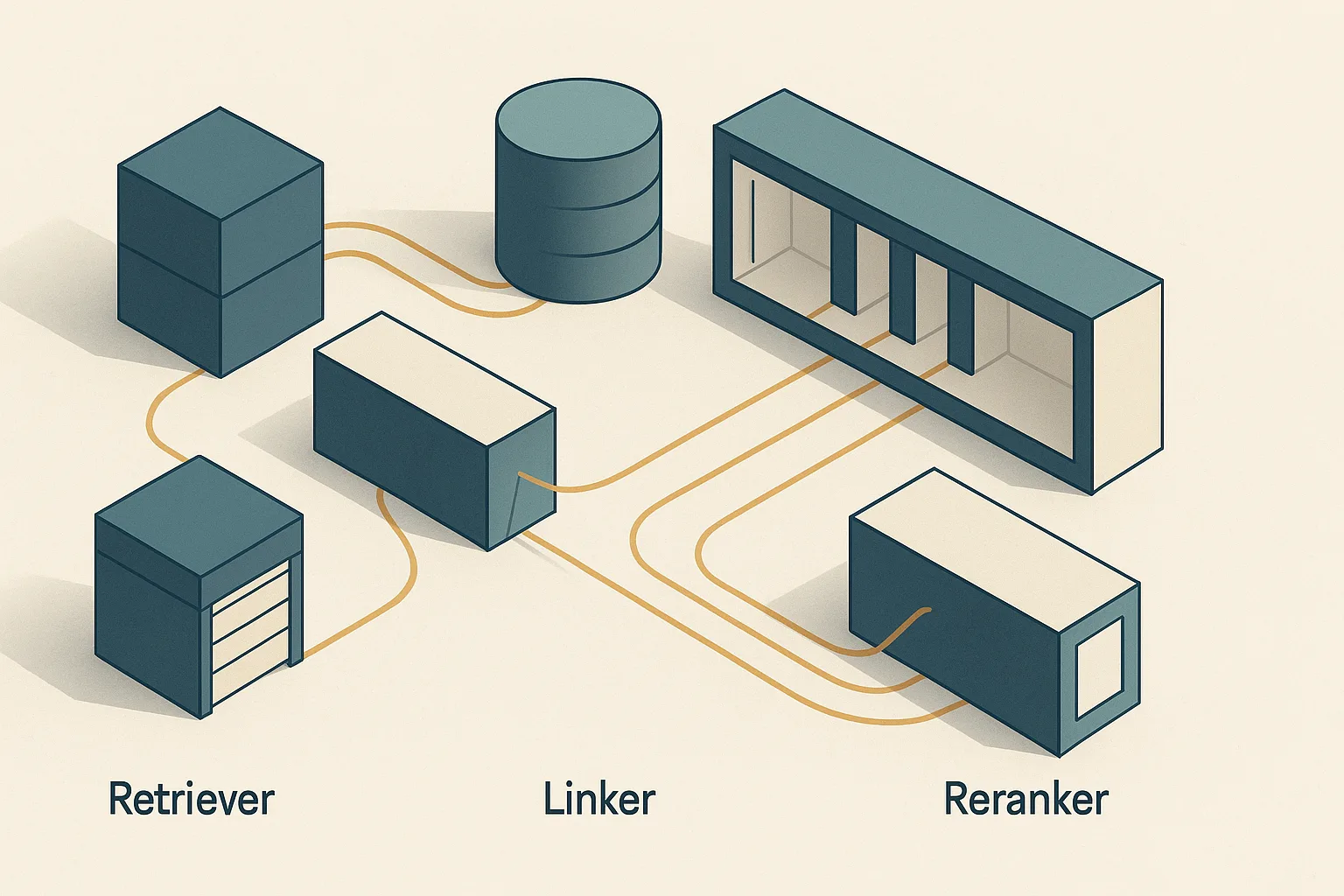
RAGchain's end-to-end control flow is modular at every stage. The pipeline does not hardwire a retriever or a reranker; it defines stage contracts that any conforming module can satisfy. A query enters, passes through one or more retriever stages that produce a candidate set, those candidates are passed through the Linker to hydrate full document content from the DB, and then a reranker reorders the hydrated set before it reaches the generation step.
ArchitectureDiagram: The diagram below shows the modular stages that the repository describes: retrievers produce candidate IDs, the Linker resolves them against the document DB, rerankers reorder hydrated passages, and generation consumes the final top-k set.
flowchart LR
Q([User Query]) --> HyDE[HyDE\nQuery Expansion]
Q --> BM25R[BM25\nRetriever]
Q --> VecR[Dense Vector\nRetriever]
HyDE --> VecR
BM25R --> Merge[Candidate Merge\nRRF / Convex Combination]
VecR --> Merge
Merge --> Linker[Linker\nVector ID → Document DB]
Linker --> Reranker{Reranker Stage\nBM25Reranker / MonoT5\nUPR / TART / LLM}
Reranker --> Gen[LLM Generation]
DB[(Document DB)] <-.-> Linker
VecIdx[(Vector Index)] <-.-> BM25R
VecIdx <-.-> VecR
Three properties make this composition safe to maintain at scale. First, each retriever writes only vector IDs into the candidate set — full document text lives in a separate DB, so swapping the retrieval index does not require migrating document storage. Second, the merge step is itself configurable (Reciprocal Rank Fusion or convex combination), so retriever weighting is a configuration decision, not a code change. Third, the reranker slot is an interchangeable module: a team can swap BM25Reranker for MonoT5 or RankGPT without touching upstream retrieval logic.
The repository confirms that this design is intentional for multi-retriever production contexts: "Great to use multiple retrievers. In real-world scenarios, you may need multiple retrievers depending on your requirements. RAGchain is highly optimized for using multiple retrievers."
Where the linker abstraction splits retrieval from the database
The Linker is the join layer between the retrieval index and the document database. Retrieval indexes — BM25, FAISS, any vector store — store vector representations and return document IDs. The document DB stores the actual text content. These two concerns have different update frequencies, different storage backends, and different consistency requirements. Coupling them, as a vanilla VectorStoreRetriever does, forces both to move together every time either changes.
RAGchain's README states the contract explicitly: "Retrieval saves vector representation of contents, and DB saves contents. We connect both with Linker, so it is really easy to use multiple retrievers and DBs." The Linker resolves IDs returned by any retriever against the authoritative document store, which means two retrievers pointing at the same corpus can share one DB connection rather than each maintaining its own document fetch path.
Pro Tip: The Linker abstraction is what makes multi-retriever setups maintainable in practice. If you add a third retriever (say, a time-weighted dense index) later, you wire it into the merge step and point its Linker at the existing DB — no document migration, no duplicate content layer. Without this split, adding a retriever typically means duplicating the corpus or accepting divergent document versions across indexes.
How multiple retrievers are combined before reranking
Multiple retrievers produce overlapping and complementary candidate sets. BM25 favors lexically precise matches; dense vector search favors semantic proximity; HyDE-style retrieval expands the query through a generated document and retrieves on that embedding. Each strategy has different recall behavior on different query types. Running all three in parallel and merging the results before reranking captures candidates that any single strategy would miss.
| Retrieval input | What it scores first | Strength in the workflow | Common failure mode |
|---|---|---|---|
| BM25 | Exact term overlap | Precision on identifiers, names, codes | Misses paraphrases and semantic variants |
| Dense / vector search | Embedding similarity | Recall on paraphrases and natural language queries | Semantic drift and duplicate flooding |
| HyDE-style retrieval | Hypothetical document embedding | Abstract or underspecified queries | Hallucinated query expansion can add noise |
The merge step takes a list of (document ID, score) tuples from each retriever and produces a single ordered candidate list. Two fusion methods are standard in the literature and both apply in RAGchain-style hybrid pipelines:
| Fusion method | Formula | Recall@5 (reported) | Sensitivity to score calibration |
|---|---|---|---|
| Reciprocal Rank Fusion (RRF) | (\text{RRF}(d) = \sum_i \frac{1}{k + r_i(d)}) | 0.695 | Low — rank-based, not score-based |
| Convex Combination (CC) | (\text{CC}(d) = \alpha \cdot s_{\text{dense}}(d) + (1-\alpha) \cdot s_{\text{sparse}}(d)) | 0.726 (α = 0.5) | High — requires score normalization |
The Recall@5 figures come from a 2026 arXiv evaluation of hybrid retrieval fusion strategies, and should not be treated as universal guarantees across corpora. RRF's immunity to score-scale mismatches makes it the safer default when combining retrievers whose score distributions differ; CC outperforms when scores are properly normalized. Both are validated fusion approaches in the hybrid retrieval literature, as confirmed by the 2022 analysis of lexical-semantic fusion functions.
Where HyDE fits in the retrieval stage
HyDE (Hypothetical Document Embeddings) is a zero-shot dense retrieval method that inserts a generation step before the embedding lookup. Given a query, an LLM generates a hypothetical document that would answer the query, and the dense retriever embeds that hypothetical document rather than the raw query. The intuition: a well-formed document embedding sits closer to real relevant documents in the vector space than a short, potentially under-specified query embedding does.
The HyDE repository reports that the method "significantly outperforms Contriever across tasks and languages" without requiring human-labeled relevance judgments. Within RAGchain's pipeline, HyDE is a retriever-stage module: it feeds its output into the same merge step that combines BM25 and standard dense results before the Linker and reranker.
Watch Out: HyDE improves recall for under-specified or abstractly phrased queries, but the generated hypothetical document can introduce noise when the LLM hallucinates a plausible-sounding but factually wrong document. This noise survives into the candidate set and enters the reranker. If your reranker is a lightweight BM25Reranker or a cross-encoder like MonoT5, it may not have the discriminative capacity to fully suppress hallucinatory HyDE candidates — especially when the real relevant documents share surface-level tokens with the hallucinated text. Audit your merged candidate set during evaluation, not just the final reranked output.
Retriever modules inside RAGchain
RAGchain's retriever surface covers four behavioral categories: lexical (BM25), dense (embedding-based), hybrid (fused), and generated-query (HyDE). Each occupies a distinct recall niche. The table below maps each category to its recall mechanism, typical latency profile, and where it adds value in a mixed-query production workload.
| Retriever type | Recall mechanism | Relative latency | Best-fit query pattern |
|---|---|---|---|
| BM25 (lexical) | Term frequency / IDF overlap | Low | Keyword-heavy, precise entity queries |
| Dense vector | Embedding cosine similarity | Low–Medium | Semantic, paraphrased, natural-language queries |
| Hybrid (BM25 + dense) | Fused rank or score | Medium | Mixed corpus, general-purpose |
| HyDE (generated-query) | Hypothetical doc embedding | High (LLM call added) | Abstract, conceptual, zero-shot queries |
RAGchain's explicit positioning is that it is "highly optimized for using multiple retrievers," because the Linker abstraction makes parallel composition cheap to configure and maintain. The project's benchmarking tooling exists precisely so teams can measure recall across these combinations without rewriting the evaluation harness each time.
BM25 and lexical retrieval paths
BM25 remains relevant in modern RAG because dense embeddings systematically underperform on queries where the exact term matters more than semantic proximity — product codes, legal clause numbers, proper names, technical abbreviations, and ambiguous short queries where meaning is highly context-dependent. RAGchain explicitly lists BM25 as a component in its retrieval and reranking ecosystem, and it surfaces both as a retriever and as a reranker (BM25Reranker), which means the same lexical scoring can operate at two distinct pipeline stages.
Pro Tip: If your production corpus contains structured identifiers — SKUs, case numbers, regulatory codes — include BM25 in your retriever composition even if dense vector recall looks adequate on average. Dense embeddings frequently miss exact-string matches because they compress text into semantic neighborhoods. BM25 finds the needle; dense retrieval finds the haystack it belongs to. The merger captures both.
Dense vector retrieval and embedding-based recall
Dense retrieval embeds both documents and the query (or in HyDE, a generated document) into a shared vector space and retrieves by approximate nearest-neighbor search. It handles paraphrases, synonym variation, and conceptual reformulations that break BM25. Within RAGchain's architecture it is the default retrieval path for semantic queries and the underlying mechanism that HyDE improves upon by substituting a richer query embedding.
Watch Out: Dense retrieval at scale produces two persistent failure modes. The first is semantic drift: embedding spaces compress meaning, so semantically adjacent but factually irrelevant documents appear in the top-k. The second is duplicate flooding: if your corpus has near-duplicate documents (versioned policy documents, syndicated news), dense retrieval fills the candidate set with redundant content, inflating the candidate count without adding recall value. Both problems arrive at the reranker as noise. Budget for deduplication at the merge step or impose a strict top-k per retriever before fusion.
Hybrid retrieval and score fusion
Hybrid retrieval merges BM25 and dense retrieval candidates using a fusion function before the Linker hydration step. The choice between RRF and convex combination is a configuration decision with measurable consequences. As reported in the 2026 hybrid retrieval evaluation, CC at α = 0.5 achieved Recall@5 of 0.726 against RRF's 0.695 in that evaluation context — a gap large enough to matter when reranker top-k inputs are small.
| Fusion approach | Score normalization needed | Tunable parameter | Sensitivity to retriever balance |
|---|---|---|---|
| Reciprocal Rank Fusion | No | k (rank smoothing constant) | Low |
| Convex Combination (α) | Yes | α ∈ [0, 1] | High |
The 2022 fusion function analysis validates both as legitimate approaches and notes that CC requires that BM25 and dense scores be normalized to a common scale before combination — without normalization, the dense retriever's score distribution typically dominates and the fusion degenerates to single-retriever dense. In RAGchain's pipeline, the fusion output is the direct input to the Linker; ordering quality at this stage determines what the reranker has to work with.
Reranker modules and ordering logic
After the Linker hydrates the merged candidate set with full document text, the reranker stage reorders those documents by relevance to the original query. RAGchain ships five reranker families: BM25Reranker, MonoT5, UPR, TART, and LLM-based reranking (the RankGPT-style permutation approach). The issue tracker confirms active development on the LLM reranker, with a refactor to LangChain LCEL underway.
| Reranker | Model type | Ordering mechanism | Relative cost | Primary strength |
|---|---|---|---|---|
| BM25Reranker | Lexical | Term overlap re-score | Negligible | Fast reorder, explainable |
| MonoT5 | Cross-encoder (seq2seq) | Pointwise relevance score | Low–Medium | Strong on factoid queries |
| UPR | Instruction-tuned LM | Generative relevance scoring | Medium | Multi-dataset generalization |
| TART | Instruction-tuned retriever | Task-aware reranking | Medium | Task-conditioned ordering |
| LLM (RankGPT) | Generative LLM | Permutation generation | High | Nuanced relevance, SOTA on benchmarks |
No single standardized RAGchain benchmark comparing all five rerankers head-to-head appears in the public repository materials; the performance evidence comes from individual papers and repos. The RankGPT repository reports that "properly instructed ChatGPT and GPT-4 can deliver competitive, even superior results than supervised methods on popular IR benchmarks," and uses pyserini to retrieve 100 passages per query before reranking via instructional permutation generation.
What each reranker is optimizing for
A retriever optimizes recall — it fetches as many potentially relevant candidates as possible within a score threshold or top-k budget. A reranker optimizes ordering — it receives a fixed candidate set and produces a better-ordered subset. These are structurally different problems. Retrievers operate at index scale (millions of documents); rerankers operate at candidate-set scale (typically 20–200 documents). Conflating the two leads to misconfigured pipelines where teams expect a reranker to compensate for a retriever that never fetched the relevant document — which is impossible by definition.
BM25Reranker applies lexical scoring to a pre-retrieved candidate set, useful when the original retrieval was purely dense and missed keyword-exact matches that appear in the already-fetched documents. MonoT5 and cross-encoder variants score each query-document pair independently (pointwise), giving a reliable relevance score per document. UPR and TART apply instruction-following objectives during scoring, generalizing better across task types. RankGPT generates a full permutation of the candidate set using an LLM's understanding of relative relevance, which is the highest-fidelity but also highest-cost approach.
Pro Tip: Do not use reranking to fix poor retrieval. If your retriever's top-20 candidate set has a ground-truth hit rate below 60%, the reranker cannot manufacture relevance that was never retrieved. Fix recall at the retrieval stage first — add a second retriever, tune fusion weights, or introduce HyDE. Reserve reranking for precision improvement: reordering a reasonable candidate set so the most relevant documents appear at positions 1–3, where LLM context windows consume them most effectively.
How LLM-based reranking changes the pipeline
LLM-based reranking (RankGPT-style) replaces a cross-encoder score with an LLM-generated document permutation. The model reads the query and a window of candidate passages, then outputs the passages in ranked order. The RankGPT repository addresses the token-limit problem with a sliding-window strategy: "We introduce a sliding window strategy for the instructional permutation generation, that enables LLMs to rank more passages than their maximum token limit." This is a mechanical change to the pipeline — rather than one reranker call per candidate set, you issue multiple LLM calls as the window slides over the full candidate list.
The quality ceiling of LLM reranking is high: the method can reason over passage content, resolve ambiguity by comparing documents against each other, and apply implicit world knowledge. That ceiling comes with a cost floor that other rerankers do not share.
Watch Out: LLM reranking amplifies cost and latency in proportion to both candidate set size and LLM token cost. With a 100-passage candidate set and a sliding window of 20, you make roughly 5 LLM calls per query. At scale, this becomes a direct SLA risk before the generation step even begins. Model providers price these calls at per-token rates that compound fast. Budget explicitly for reranker token cost before choosing LLM reranking in latency-sensitive paths, and consider batching or caching reranker results for high-frequency queries.
How reranker choice affects ambiguous queries and long context windows
Ambiguous queries expose the gap between retrieval and reranking most sharply. A query like "model performance" could legitimately match documents about financial models, ML training metrics, or physical model-making. The retriever fetches broadly because the embedding is semantically diffuse; the reranker must disambiguate by examining document content in relation to the query. A BM25Reranker cannot do this — it has no semantic model. MonoT5 handles it through fine-tuned relevance scoring. UPR and TART handle it through instruction-conditioned task understanding. RankGPT handles it through direct comparative reasoning.
The RAGchain Linker abstraction matters here because reranker quality depends on what the candidate documents actually say — not just their vector proximity. By splitting retrieval (which stores vectors) from the DB (which stores text), RAGchain ensures that every reranker receives full document content through the Linker, regardless of which retriever sourced the candidate. A multi-retriever configuration where BM25, dense, and HyDE each contribute candidates all arrive at the reranker with hydrated text, making the reranker's job well-defined.
Context window constraints compound the problem at scale. As the RankGPT sliding-window mechanism demonstrates, even LLM-based rerankers hit practical limits when candidate lists grow beyond the model's context capacity. This means the merge step's top-k discipline directly controls reranker feasibility.
Production Note: For SLA-sensitive production RAG stacks, reranker choice determines your p95 latency more than retriever choice does, because reranking is sequential (every candidate passes through the reranker) while retrieval can be parallelized across indexes. Set a hard top-k ceiling at the merge step (typically 50–100 candidates entering the reranker), and treat that ceiling as an SLA control variable. If LLM reranking blows your p95 budget, downgrade to MonoT5 for ambiguous queries and reserve LLM reranking for asynchronous or low-traffic paths.
HyDE, OCR loaders, and time-aware RAG as workflow extensions
HyDE, OCR loaders, and time-aware RAG each extend a different dimension of the RAGchain pipeline without altering its core structure. HyDE expands what queries can reach in the vector space. OCR loaders expand which documents enter the corpus at all. Time-aware RAG changes how recency affects candidate scoring. All three integrate as first-class modules in RAGchain's architecture, confirmed by the README listing: "Easy benchmarking, multiple retrievals, reranker, time-aware RAG, and so on."
Bottom Line: These three extensions change recall and relevance through orthogonal mechanisms — query-side expansion (HyDE), corpus-side expansion (OCR loaders), and time-side filtering (time-aware RAG) — but none of them require restructuring the retriever → Linker → reranker → generation pipeline. Teams can adopt each independently and combine them without pipeline refactoring.
How OCR loaders expand the retrievable corpus
OCR loaders solve a corpus completeness problem: documents that exist only as scanned PDFs or image-heavy files are invisible to a text-based retrieval pipeline unless their content is extracted first. RAGchain explicitly names Nougat and Deepdoctection as supported OCR loader modules. Both produce text from document images, which then flows into the standard ingestion path — chunked, embedded, stored in the vector index and document DB.
Pro Tip: For corpora that include scientific papers, regulatory filings, or internal documentation scanned from paper, OCR loaders are the prerequisite that makes retrieval meaningful at all. Without them, dense retrieval and BM25 both return zero signal on those documents. Nougat is designed for scientific PDFs with complex layouts including equations; Deepdoctection handles general document layouts including tables and multi-column formats. Match the loader to your corpus structure rather than using one universally.
How time-aware RAG changes freshness and relevance
Time-aware RAG introduces a recency signal into the retrieval or reranking stage, allowing the pipeline to prefer more recent documents when temporal currency matters. RAGchain includes this as a supported feature module in the main repository. The mechanism applies a time-based weight or filter to the candidate set, either at the retrieval stage (filtering out documents older than a threshold) or as a reranking factor (penalizing older documents in the final ordering).
Watch Out: Time-aware retrieval creates recency bias that degrades quality on queries where the most relevant document is an authoritative older source — legal precedents, foundational technical specifications, historical event records. A strict recency filter discards relevant old documents entirely. A soft recency weight suppresses them. Audit whether your query distribution actually benefits from time weighting before enabling it globally; in many production corpora, relevance and recency are weakly correlated or negatively correlated for the highest-stakes query types.
Trade-offs, failure modes, and production fit
Composing multiple retrievers and rerankers inside RAGchain is not free. Each component added increases candidate set size, merge complexity, Linker resolution overhead, and reranker input volume. The failure modes compound: HyDE adds LLM latency before retrieval; multi-retriever fusion multiplies the candidate set; LLM reranking consumes tokens proportional to that candidate set. Teams that add all three simultaneously without budgeting for the cascade create a pipeline that is correct in architecture but unusable in production SLAs.
The fusion evidence quantifies one dimension: CC at α = 0.5 produced Recall@5 of 0.726 versus RRF's 0.695 in a controlled evaluation (arXiv 2604.01733), but the absolute recall gain from adding a third retriever to an already-strong two-retriever setup diminishes and the candidate set grows linearly. The RankGPT sliding-window mechanism exists precisely because candidate explosion is a constraint that reaches LLM context limits at realistic candidate counts.
| Configuration | Recall ceiling | Latency profile | Cost profile | Best deployment context |
|---|---|---|---|---|
| Single dense retriever + BM25Reranker | Moderate | Low | Low | High-throughput, keyword-heavy corpora |
| BM25 + dense hybrid + MonoT5 | High | Medium | Medium | General-purpose, mixed query types |
| BM25 + dense + HyDE + MonoT5/UPR | High+ | Medium–High | Medium–High | Semantic-heavy, abstract queries |
| BM25 + dense + HyDE + LLM reranker | Highest | High | High | Low-traffic, high-quality-critical paths |
| Any config + time-aware + OCR loaders | Corpus-dependent | Adds ingestion overhead | Adds ingestion cost | Document-diverse, freshness-sensitive corpora |
Latency, cost, and candidate-set explosion
Candidate-set explosion is the most common production failure mode in multi-retriever RAGchain setups. If three retrievers each return top-50 candidates before deduplication, the merge step can produce 150 candidates (minus duplicates). A sliding-window LLM reranker processing that set in windows of 20 issues multiple LLM calls per query. The RankGPT repository uses that sliding-window strategy specifically because candidate lists can exceed token limits.
Watch Out: The interaction between HyDE (LLM call before retrieval) and LLM reranking (multiple LLM calls after retrieval) creates a cost multiplier that is non-obvious from reading the individual module descriptions. Budget both ends of the pipeline explicitly. For most production configurations, one end should be a lightweight model: if you use LLM reranking, use embedding-based HyDE with a small model; if you use a large LLM for HyDE, use a cross-encoder for reranking.
When RAGchain is the right architectural choice
RAGchain is the right choice when the retrieval problem requires compositional flexibility that a single-retriever chain cannot provide — specifically, when query diversity, corpus heterogeneity, or ordering quality requirements demand different retrieval strategies for different query types, and when the team needs to benchmark and swap those strategies without pipeline rewrites.
The RAGchain README positions this explicitly: "It is really easy to use multiple retrievers and DBs," and the benchmarking tooling exists so teams can evaluate retrieval/reranking combinations against each other systematically.
Production Note: RAGchain is a strong fit for production systems where the corpus spans multiple document types (text, PDFs, images), queries span semantic and keyword patterns, and the engineering team needs to iterate on retrieval strategy without re-ingesting data or restructuring the pipeline. It is not the right choice for simple single-source QA systems where a standard LangChain
RetrievalQAchain is maintainable and sufficient — the Linker abstraction and multi-retriever composition add operational complexity that flat pipelines don't need.
Operational checklist for teams evaluating RAGchain
Before adopting RAGchain, teams should verify fit against the actual requirements of their production system. The modular architecture adds operational surface area; the decision should be driven by whether that surface area is needed.
| Evaluation criterion | RAGchain fit | When to proceed | When to reconsider |
|---|---|---|---|
| Multi-source corpus (text + PDF + images) | Strong — OCR loaders built in | Corpus includes scanned or image-heavy docs | Plain-text corpus only |
| Multi-retriever composition needed | Strong — core design goal | Queries span keyword and semantic patterns | Single-index dense retrieval is sufficient |
| Reranking depth required | Strong — 5 reranker families | Ordering quality is a product SLA | Top-1 recall is all that matters |
| Time-aware freshness needed | Supported | Corpus freshness materially affects answer quality | Static corpus, no recency requirements |
| LangChain compatibility required | Native — built as extension | Existing LangChain infrastructure in place | Fully custom pipeline without LangChain |
| Benchmarking across configurations needed | Built-in | Team needs to compare retriever/reranker combos | One-shot deployment, no iteration planned |
| Operational complexity tolerance | Medium-high | Dedicated ML engineer maintains the pipeline | Small team, minimal ops capacity |
What the repository and docs do not spell out
The RAGchain README states the Linker design and lists supported modules, but it does not publish a formal control-flow diagram, an exhaustive module interaction contract, or a stage-by-stage latency profile. The documentation lives in a separate docs repository, which means the implementation details are distributed across the README, the docs repo, and the issue tracker (where the LLM reranker LCEL refactor in issue #332 reveals active architectural evolution).
Most competitor coverage of RAGchain stops at "it supports multiple retrievers and rerankers," which is accurate but describes only the feature surface. What competitor coverage omits is the control-flow logic: the Linker is not a routing layer — it is a join that separates the retrieval index from document storage, allowing any retriever to contribute candidates that are all hydrated from the same document DB before reaching the reranker. This is the architectural decision that makes the multi-retriever configuration maintainable rather than just theoretically possible.
Pro Tip: When reading RAGchain's source or docs, model the system as three independent layers: (1) the retrieval layer, which produces document IDs and scores from whatever index strategy you configure; (2) the storage layer, which holds the full document content in a DB; and (3) the ranking layer, which reorders the hydrated candidate set. The Linker is the seam between layers 1 and 2. The reranker is the mechanism of layer 3. Generation sits outside all three. Keeping these three layers mentally separate is what the competitor coverage fails to do — and conflating them is what leads engineers to misconfigure multi-retriever setups or expect rerankers to fix retrieval recall.
FAQ
How does reranking improve RAG?
Reranking improves RAG by improving the ordering of an already-retrieved candidate set, not by adding new documents to it. Retrievers optimize for recall — they surface as many potentially relevant documents as the top-k budget allows. Rerankers optimize for precision at the top of the list: they consume the retrieved candidates and output a reordered set where the most relevant documents appear first. The LLM generation step typically sees only the top-3 to top-5 documents from that reranked list, so a reranker that moves the correct document from position 12 to position 2 directly improves answer quality. For example, RankGPT retrieves 100 passages per query and reranks them via instructional permutation generation — the final generator never sees the 97 documents that the reranker deprioritized.
What is HyDE in retrieval-augmented generation?
HyDE (Hypothetical Document Embeddings) is a zero-shot dense retrieval enhancement where an LLM generates a hypothetical document that would answer the query, and that generated document's embedding is used for the nearest-neighbor lookup instead of the raw query embedding. This is useful because a query like "what causes transformer attention to fail at long sequences?" is a short, sparse text while the relevant documents are long, dense technical passages. Embedding a generated technical passage brings the query representation closer to the document representations in vector space. HyDE "significantly outperforms Contriever across tasks and languages" without requiring labeled training data, but it adds an LLM call before retrieval and can introduce noisy candidates when the generated hypothetical document contains hallucinated content.
What is the difference between a retriever and a reranker?
A retriever operates at index scale — it searches millions of documents and returns a top-k candidate set using a fast approximate method (BM25 scoring or ANN search). A reranker operates at candidate-set scale — it takes the top-k documents already returned by the retriever (typically 20–200) and applies a more computationally expensive model to reorder them by relevance. Retrievers trade accuracy for speed; rerankers trade speed for accuracy. They are complementary stages in the same pipeline, and conflating them leads to expecting a reranker to surface documents the retriever never fetched.
How does multi-retrieval work in RAG?
Multi-retrieval runs several retrieval strategies in parallel against the same corpus — typically BM25, dense vector search, and optionally HyDE. Each retriever returns its own top-k candidate set with associated scores. A fusion function (RRF or convex combination) merges these candidate lists into a single ordered set, deduplicates by document ID, and passes the merged set to the Linker for document hydration and then to the reranker. The benefit is that different retrievers complement each other: BM25 catches exact-term matches that dense retrieval misses; dense retrieval catches semantic variants that BM25 misses; HyDE catches conceptually relevant documents for abstractly phrased queries. Multi-retrieval with fusion consistently outperforms any single retriever on mixed-query corpora.
Sources and references
- RAGchain GitHub Repository — Primary source: project README, module descriptions, and architectural design for retrieval/reranker/Linker composition
- RAGchain Documentation Repository — Supplementary implementation documentation separate from the main codebase
- RAGchain Issue #332: Refactor LLM reranker using LangChain LCEL — Confirms active development status and architectural evolution of the LLM reranker module
- HyDE GitHub Repository (texttron/hyde) — Primary source for Hypothetical Document Embeddings method description and benchmark comparisons
- RankGPT GitHub Repository (sunnweiwei/RankGPT) — Source for LLM-based permutation reranking methodology, sliding-window strategy, and MS MARCO evaluation data
- arXiv 2604.01733 — Hybrid Retrieval Fusion Evaluation (2026) — Source for Recall@5 benchmark numbers comparing RRF (0.695) and Convex Combination (0.726) at α = 0.5
- arXiv 2210.11934 — Fusion Functions for Hybrid Retrieval (2022) — Foundational analysis of RRF and convex combination score fusion methods for lexical-semantic hybrid retrieval
- arXiv 2403.16435 — UPR / InstUPR Evaluation — Source for positioning UPR and TART-Rerank as instruction-tuned reranking approaches
Keywords: RAGchain, HyDE, reranker, multi-retriever, Linker abstraction, BM25, BM25Reranker, MonoT5, UPR, TART, RankGPT, Reciprocal Rank Fusion, convex combination, time-aware RAG, OCR loaders, LangChain, vector stores, dense retrieval, hybrid retrieval, reranking pipeline