AI & ML
Progressive scoping restricts tool-call authority to execution-time context, effectively curbing prompt injection risks; however, static least-privilege policies often fail when agents require dynamic 'just-in-time' token provisioning.
15 min read
AI & ML
In-house agent orchestration typically hits a 'complexity ceiling' at 3+ concurrent autonomous tools, where custom state management and error propagation become as costly as the original development — often requiring 0.5 to 1.0 dedicated FTE for maintenance — but buying into a framework risks vendor lock-in that may restrict model-agnostic flexibility.
13 min read
AI & ML
MCP provides standardized context-sharing and resource discovery natively, whereas REST requires bespoke schema definition per agent, leading to 3x higher integration overhead in multi-agent environments—but MCP lacks the robust mature ecosystem for long-haul asynchronous transport compared to gRPC-backed A2A.
14 min read
AI & ML
Self-correction loops in reasoning models often suffer from 'confirmation bias' where the model's policy distribution collapses toward high-confidence, incorrect tokens — reducing overall accuracy compared to a single-pass inference baseline.
14 min read
AI & ML
Routing to reasoning models (like DeepSeek-R1) for complex tasks while falling back to GPT-4o for standard queries optimizes TCO by 30-50% compared to a uniform high-intelligence model deployment, provided the router latency is <50ms.
13 min read
AI & ML
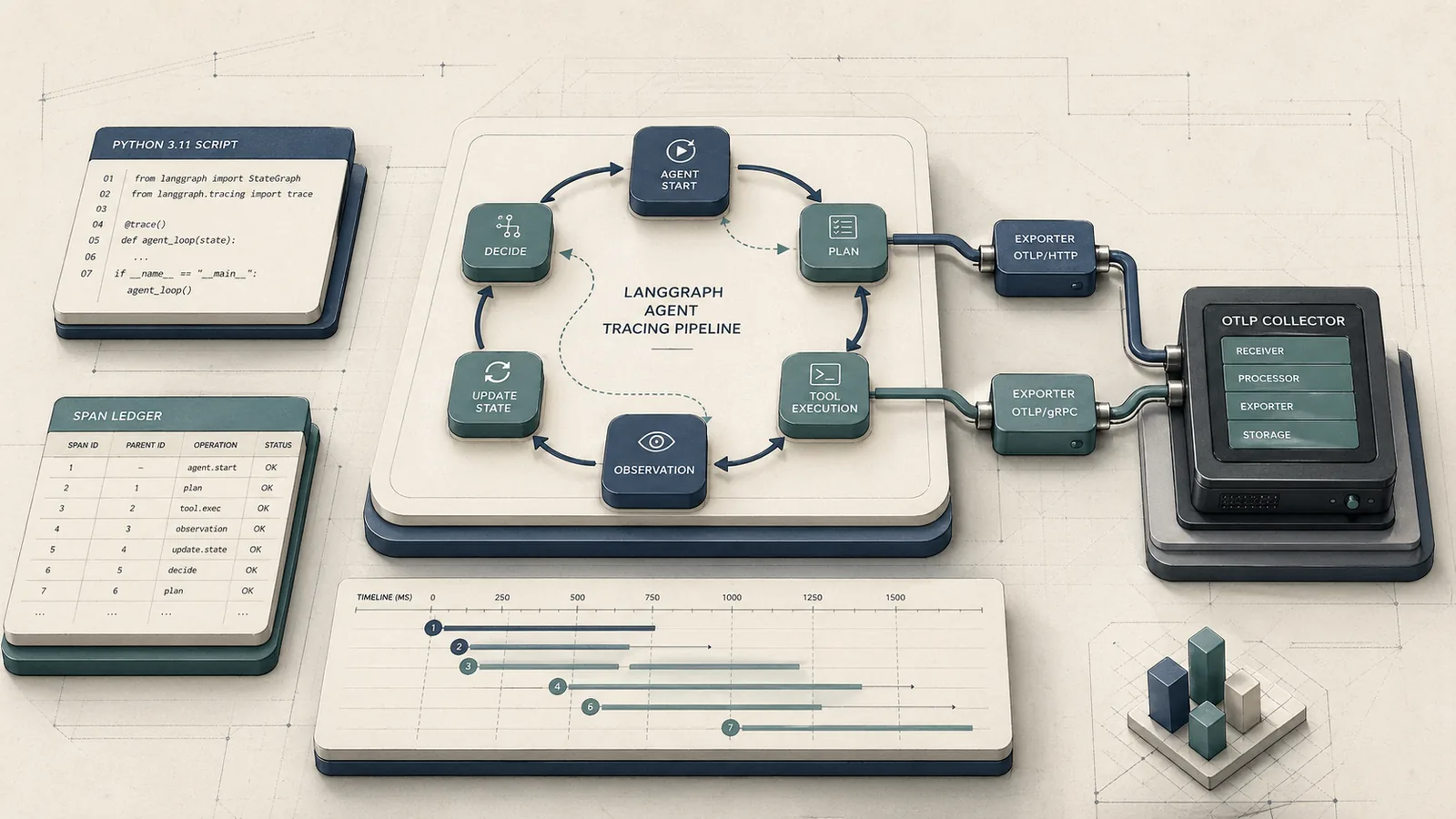
Instrumenting LangGraph state-transitions using OpenTelemetry manual spans ensures that recursive cycles in agent logic are correctly parented in trace backends — otherwise, child spans often orphan, rendering agent execution loops unreadable in standard APM tools.
17 min read
AI & ML
Dynamic agentic graph compilers replace rigid Directed Acyclic Graphs (DAGs) with runtime-mutable execution plans that treat agent control flow as first-class code — enabling self-correcting loops — but introduce significant challenges in deterministic state management and recursive infinite loop prevention.
16 min read
AI & ML
Managed agent platforms now bundle orchestration, memory, tracing, evaluation, and governance, which can cut time-to-production versus custom builds — but ML6’s 2026 guide says custom solutions still win when you need advanced observability, strict cost control, portability, or complex orchestration, so the decision hinges on operating burden more than raw capability.
20 min read
AI & ML
Increasing test-time compute through MCTS or rejection sampling yields diminishing logarithmic returns on reasoning benchmarks (e.g., AIME) after a 10x compute threshold, where token-level variance outweighs the logical gain of exhaustive path exploration.
15 min read
AI & ML
Current reasoning benchmarks often report aggregate accuracy without factoring 'inference-compute-per-token', masking the fact that models like o3 effectively cost 3x per correct answer on AIME 2024 compared to high-efficiency specialized runners.
9 min read
AI & ML
Chain-of-Thought (CoT) provides the lowest latency and cost for standard logic, whereas Reflexion adds significant overhead (3-5x tokens) but outperforms CoT by up to 20% on complex multi-step debugging tasks.
9 min read
AI & ML
Reasoning models like DeepSeek R1 and OpenAI o1 achieve higher accuracy on domain-specific benchmarks by trading 5x-10x higher latency per request compared to standard autoregressive models, significantly shifting the cost-per-successful-inference equation for RAG-augmented agentic workflows.
12 min read