AI & ML
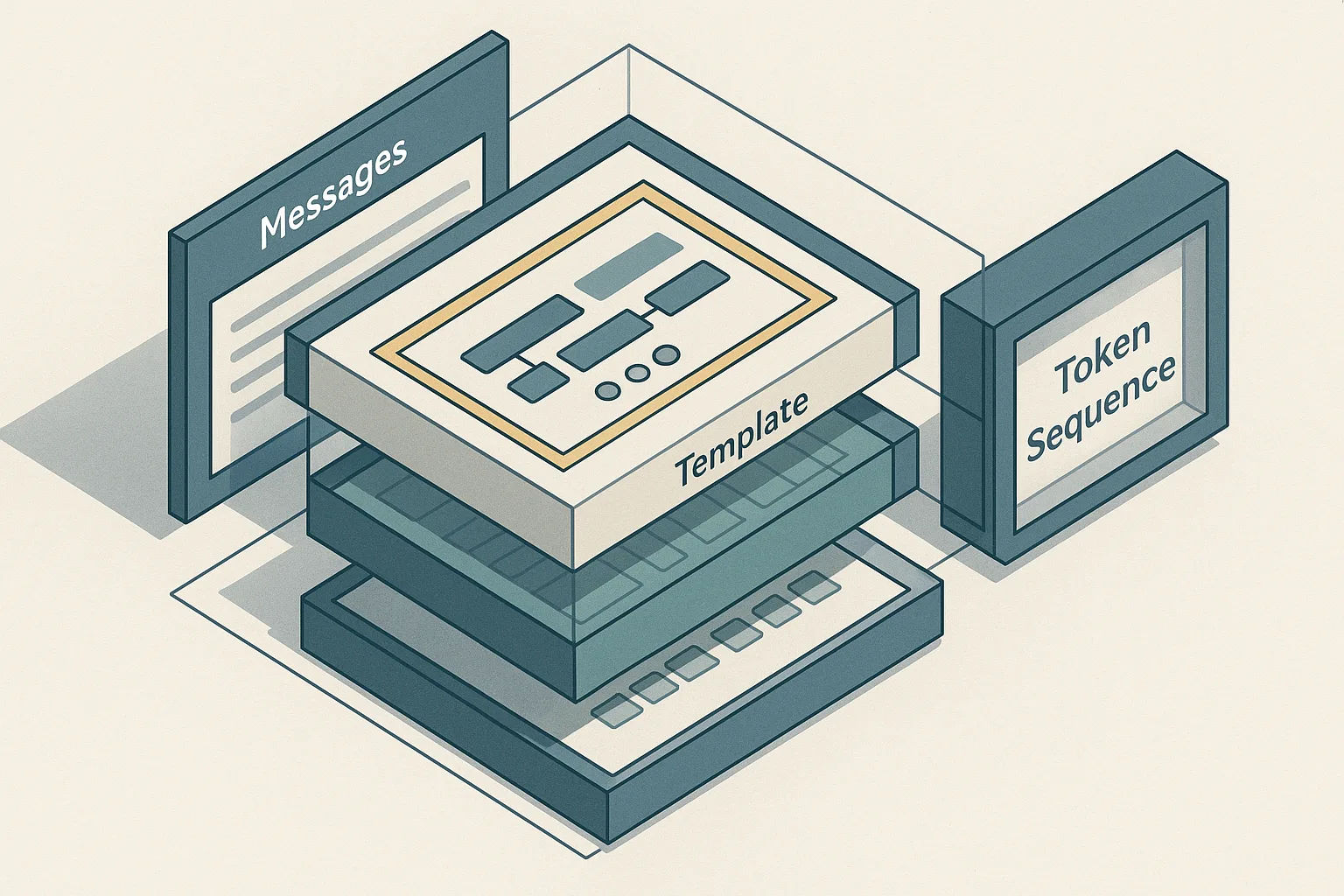
Qwen-style tool templates encode tool calls and tool responses as explicit structured chat turns, which lets agentic SFT learn when to emit function calls versus natural language — but that same rigid structure makes tokenization, message ordering, and role boundaries critical to correctness.
24 min read
AI & ML
Axolotl’s multi-node path works either through Accelerate/FSDP2 config or torchrun rendezvous, and for InfiniBand the docs explicitly recommend torchrun with NCCL_IB_DISABLE=0 and tuned NCCL_SOCKET_IFNAME/NCCL_BUFFSIZE settings — but every node must share the same Axolotl commit and config, and the launcher choice changes how you debug NCCL and rendezvous failures.
19 min read
AI & ML
SimPO replaces the reference-log-ratio term with a reference-free reward and the released repo reports stronger results than DPO variants on AlpacaEval 2, MT-Bench, and Arena-Hard — but the authors also caution that performance depends heavily on learning-rate and beta tuning, so the method is not plug-and-play.
22 min read
AI & ML
Qwen3-Coder-Next’s value proposition is benchmark movement on coding-agent evaluations such as SWE-Bench and Terminal-Bench, but the article needs to separate reported benchmark gains from what the paper actually proves about instruction-tuning design and agentic generalization.
19 min read
AI & ML
In 2026, the main differentiators are not just benchmark averages but retrieval quality, multilingual coverage, dimensionality, and operational constraints — OpenAI text-embedding-3-small is the cost-effective default, Voyage is positioned for top retrieval accuracy, and BGE-M3 is the common self-hosted multilingual pick, but model choice is sticky because re-embedding an existing corpus is expensive.
22 min read
AI & ML
OpenRLHF can cover a large slice of RLHF/post-training work because it combines Ray, vLLM, and DeepSpeed into a production-ready stack — but once you need unusual model topologies, heavy multi-turn orchestration, or tighter control over throughput and scheduling, the hidden cost shifts from licensing to platform engineering and GPU utilization.
24 min read
AI & ML
ORPO’s monolithic objective folds supervised and preference learning into a single optimization path, removing the separate reference model used by DPO-style methods — which simplifies the training stack and can reduce orchestration overhead, but shifts more of the stability burden onto loss design and tuning.
23 min read
AI & ML
The economic break-even for self-managed LoRA usually depends less on adapter training cost than on ongoing platform labor, governance, and model-lifecycle overhead, so the cheapest per-token path can still be the most expensive operating model once staffing and reliability are counted.
21 min read
AI & ML
Managed RAG platforms win when the organization values faster time-to-value, vendor support, and lower specialist headcount more than total control, but the open-source build path pays off only when the team can absorb ongoing platform engineering, integration, and maintenance costs.
24 min read
AI & ML
When frameworks are tested under identical models, embeddings, retrievers, and query budgets, the real differences show up less in answer accuracy and more in orchestration overhead and token efficiency, with benchmarked gaps on the order of milliseconds and hundreds of tokens per query.
18 min read
AI & ML
Late chunking preserves global context by embedding the full document before slicing, while sentence-window retrieval keeps the similarity unit small but restores surrounding sentences at prompt time — contextual retrieval tends to preserve semantic coherence better, but late chunking is more efficient and can sacrifice completeness if the downstream window is too small.
24 min read
AI & ML
The economic breakpoint is usually not the evaluator itself but the hidden operating cost of keeping golden sets, regression gates, and production trend dashboards current — buy when you need fast time-to-value and shared observability, build when your team can absorb ongoing maintenance, model-judge spend, and platform engineering overhead.
20 min read